
随着大语言模型的广泛应用,如何在低成本硬件上实现高性能、高并发的本地化部署成为关键需求。vLLM是一个开源的大语言模型推理库,它能够显著提升大语言模型推理的速度和效率,让开发者可以更高效地部署和运行大语言模型,尤其对于多GPU跑LLM的优化表现突出。在Linux操作系统,Intel在vLLM上提供完整的打包步骤和镜像,方便用户进行本地部署大模型,支持多用户多并发,性能优异。
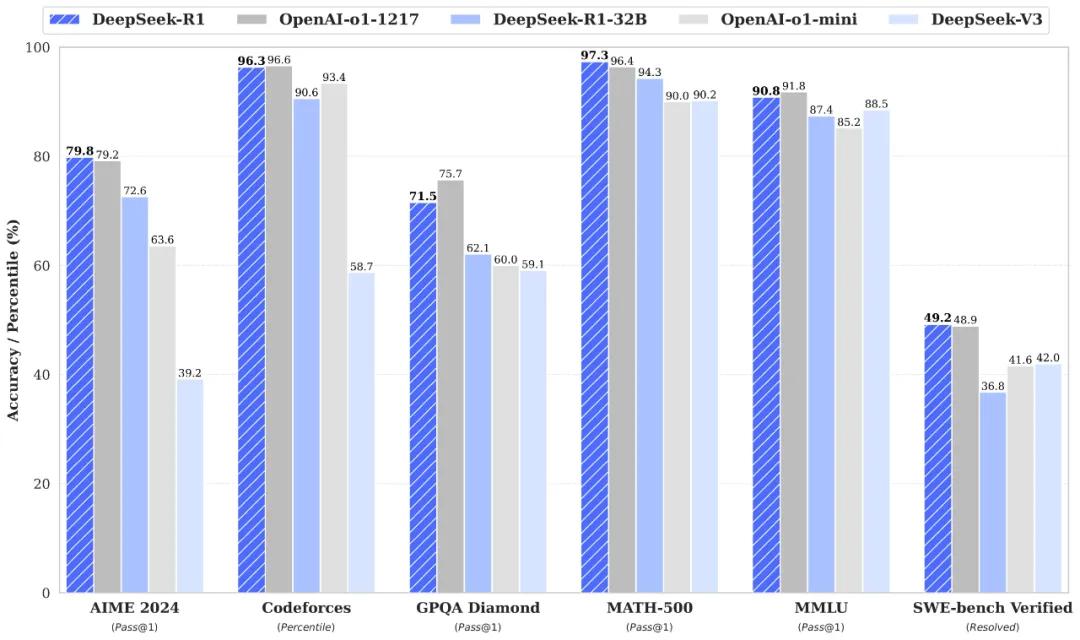
在众多大模型里,DeepSeek-R1-32B在数学推理、代码生成与逻辑分析等场景表现尤为突出,实测性能接近 70B 级别模型,成为目前DeepSeek蒸馏模型中的理想优选!
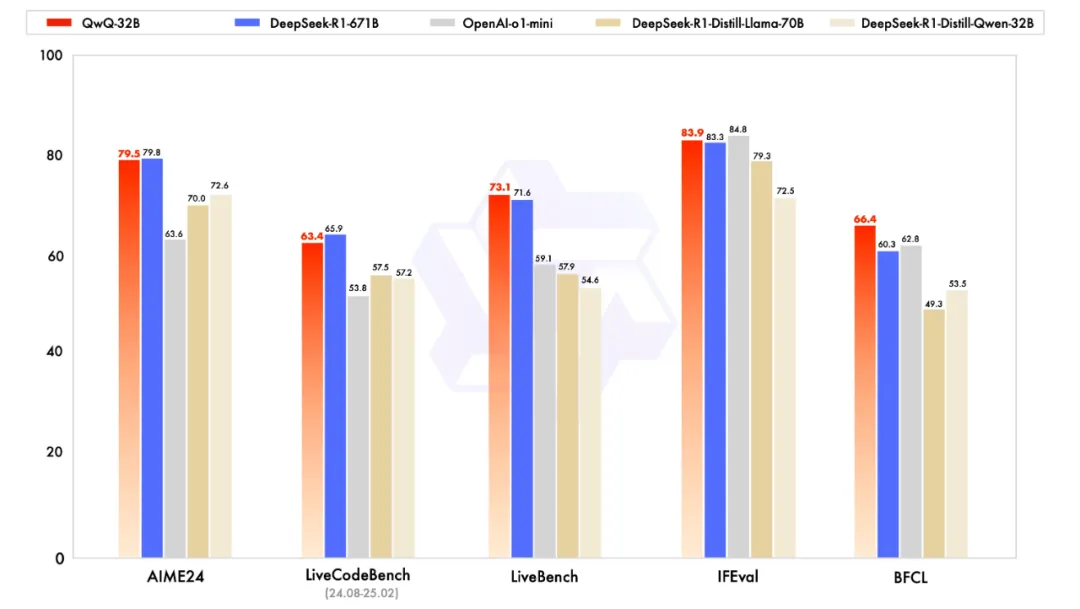
而阿里Qwen团队发布的QwQ-32B大语言模型,一经推出便广受关注,在测试数学能力的AIME24评测集上,以及评估代码能力的LiveCodeBench中,QwQ-32B表现与DeepSeek-R1相当,远胜于o1-mini及相同尺寸的R1蒸馏模型。可以说,QwQ-32B模型是目前业界表现更为突出、被广泛运用的强悍选择。下面就跟大家详细介绍如何通过Intel在vLLM上提供的完整打包方案和镜像本地部署DeepSeek 32B和QWQ 32B模型。本地部署32B模型前,需先确认本机具备至少20G显存以确保充分发挥性能,此次演示使用的配置为:

(以上整机配置成本仅约11720元起,具备更强的性价比优势)
本地部署DeepSeek 32B模型具体步骤:
1、确认OS版本为:Ubuntu 22.04 + Intel Out-of-Tree GPU drivers.
2、在BIOS设置中,找到“PCI Express Configuration”并且打开“PCIE Resizable BAR Support”
3、进行UBUNTU安装:
1)安装Ubuntu22.04.1+Kernel 6.5.0-35-generic
—下载https://old-releases.ubuntu.com/releases/22.04.1/ubuntu-22.04.1 desktop-amd64.iso
—使用烧录工具 (比如rufus) 来创建U-Disk
—安装Ubuntu
—确保网络可以正常使用
2)安装 Intel Out-of-Tree GPU driver
· # Install the Intel graphics GPG public key
· wget -q0 - https://repositories.intel.com/gpu/intel-graphics.key |
· sudo gpg --yes --dearmor --output /usr/share/keyrings/intel-graphics.gpg
· # Configure the repositories.intel.com package repository
· echo "deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel graphics.gpg] https://repositories.intel.com/gpu/ubuntu jammy unified" |
· sudo tee /etc/apt/sources.list.d/intel-gpu-jammy.list
· # Update the package repository metadata
· sudo apt update
· sudo apt install -y intel-i915-dkms intel-fw-gpu
3)Configuring Render Group Membership
· sudo gpasswd -a ${USER} render
· sudo reboot
4)验证Intel® Arc™ A770 PCIe Configuration Space
· #List the VGA device PCIe bus address to confirm 2x A770s are detected
· sudo lspci | grep -i vga
o 03:00.0 VGA compatible controller: Intel Corporation Device 56a0 (rev 08)
o 04:00.0 VGA compatible controller: Intel Corporation Device 56a0 (rev 08)
· sudo lspci -s 03:00.0 -vvv
· #You should see an output as following:
o Capabilities: [420 v1] Physical Resizable BAR
· BAR 2: current size: 16GB, supported: 256MB 512MB 1GB 2GB 4GB 8GB 16GB
5)Install Docker – 或参考https://docs.docker.com/engine/install/ubuntu/
· # Add Docker's official GPG key:
· sudo apt-get update
· sudo apt-get install ca-certificates curl
· sudo install -m 0755 -d /etc/apt/keyrings
· sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
· sudo chmod a+r /etc/apt/keyrings/docker.asc
· # Add the repository to Apt sources:
· echo
· "deb [arch=$(dpkg --print-architecture) signed- by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu
· $(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" |
· sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
· sudo apt-get update
· sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx plugin docker-compose-plugin
4、Huggingface 下载 32B-AWQ 模型
1)访问
https://huggingface.co/Valdemardi/DeepSeek-R1-Distill-Qwen-32B-AWQ
2)下载模型到文件目录/model(如果没有该目录,请在root模式下创建/model)
3)所有镜像和脚本,已经打包上传到百度网盘:通过网盘分享的文件:model.zip 链接: https://pan.baidu.com/s/1a019IPXap5OmnPM9WICwBg?pwd=mp8w 提取码: mp8w
5、载入镜像
1)载入Intel提供的LLM后端镜像:
—把ipex-llm-serving.tar.gz 拷贝到本机
—加载docker镜像:sudo docker load -i ipex-llm-serving.tar.gz
2)载入Intel提供的前端镜像:
—把openwebui.tar.gz 拷贝到本机
—加载docker镜像:sudo docker load -i openwebui.tar.gz
3)确认镜像加载成功:加载成功后sudo docker images 应该出现以下打印:

6、启动容器Pod
1)启动后端容器:
—把create-llm.sh 拷贝到本机
—启动脚本:sudo bash create-llm.sh
—如果第一次创建,那么将会有打印,这是正常现象:Error response from daemon: No such container: llm-backend
—确认pod已经启动:

2)启动前端容器:
—把create-ui.sh 拷贝到本机
—启动脚本:sudo bash create-ui.sh
—如果第一次创建,那么将会有打印,这是正常现象:Error response from daemon: No such container: llm-frontend
—确认pod已经启动:

7、启动应用
1)启动后端应用:
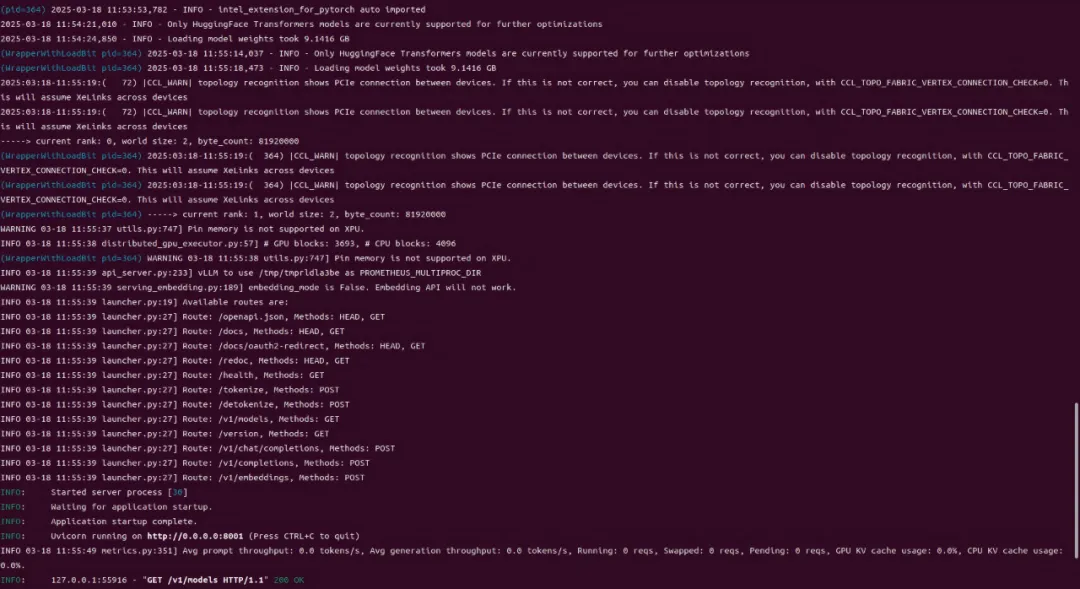
—新建shell窗口,执行命令docker exec -it llm-backend bash /model/ds.sh
—程序开始后等待约数分钟,出现如下打印为正常启动:
2)启动前端应用:
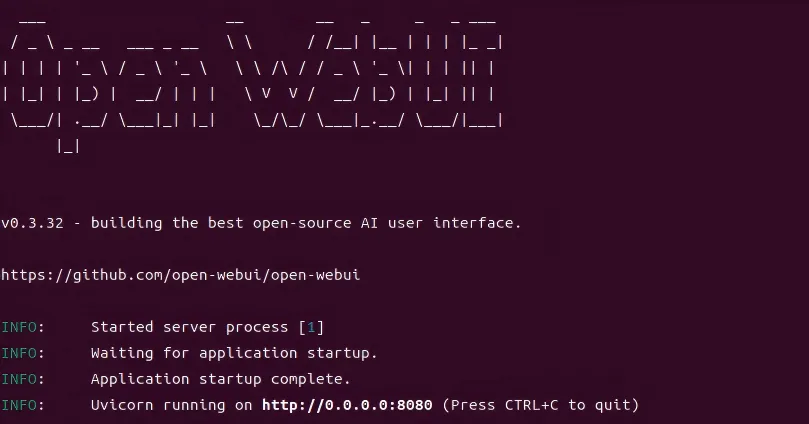
—前端应用为容器自启动,执行命令docker logs llm-frontend,出现下图的打印为已经启动:
3)在启动完前后端后,需要手动设置显存频率和CPU频率:
— 设置CPU频率,以Ultra 7 265K为例
cpupower frequency-set -d 3.9GHz
—设置显存频率
xpu-smi config -d 0 -t 0 --frequencyrange 2400,2400
xpu-smi config -d 1 -t 0 --frequencyrange 2400,2400
10、交互
1)图形界面打开firefox浏览器,输入地址127.0.0.1:8080,跳转本地前端页面:
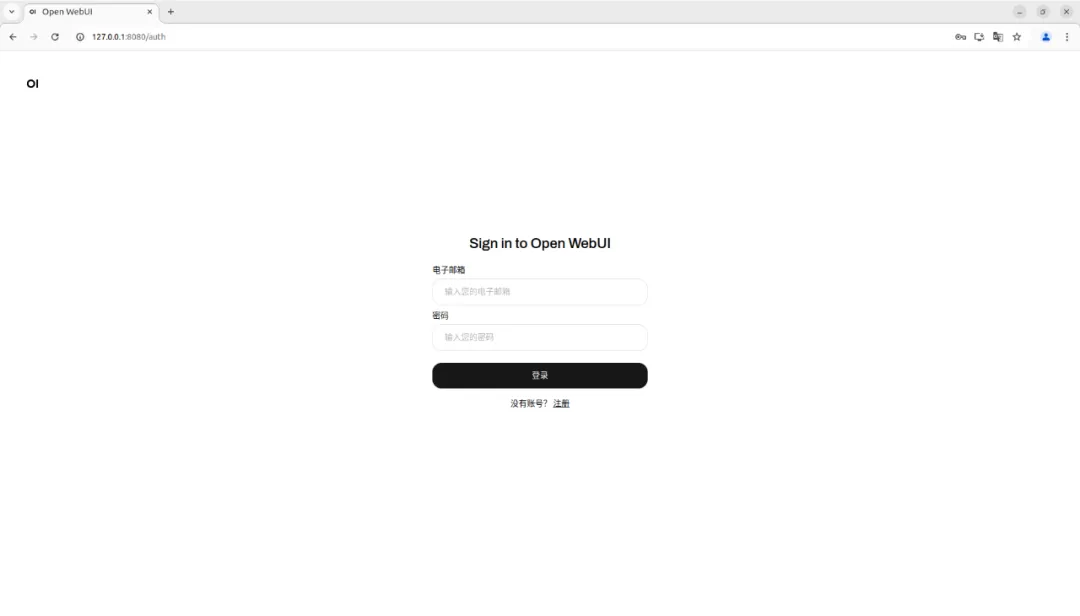
Email填写admin@intel.com, Password填写admin完成登录,如果界面是注册界面,则按照个人偏好完成管理员注册即可。
2)如果后端服务正常,在登陆后会在左上角下拉菜单里看到启动的模型,点击模型名称应用该模型:
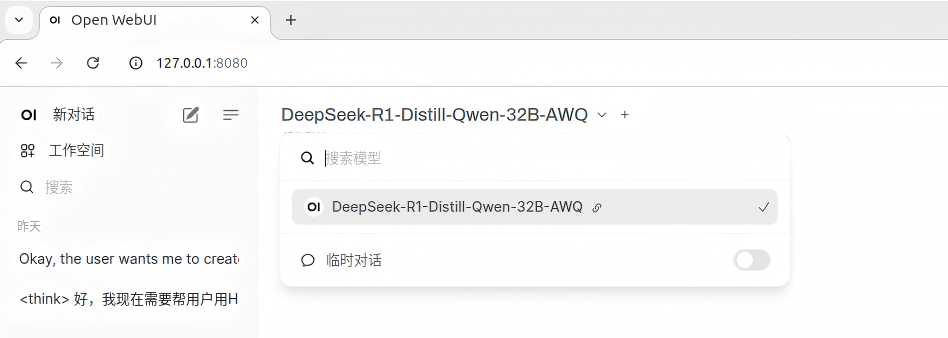
完成以上操作启用对应模型,输入Prompt即可进行推理及内容输出。
如果需要进行QwQ-32B-AWQ模型的本地部署,只需要基于以上步骤的基础,进行3步操作:
1)下载QwQ-32B-AWQ模型
https://huggingface.co/Qwen/QwQ-32B-AWQ,下载完成后将模型放在/model下
2)修改ds.sh
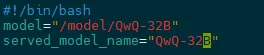
3)启动后端,选择模型名称应用该模型
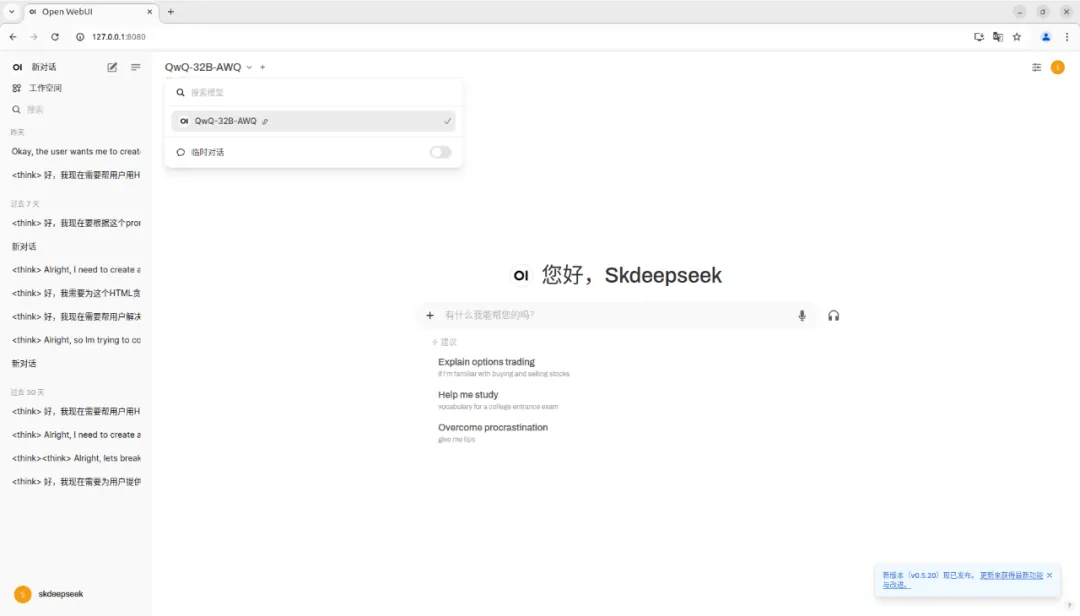
以下为MS-iCraft Z890 Pacific搭载双Intel Arc A770显卡运行DeepSeek-R1-Distill-Qwen-32B和QwQ-32B-AWQ的实机截图,实测输出Token数为27.2/S,充分满足日常工作需求。
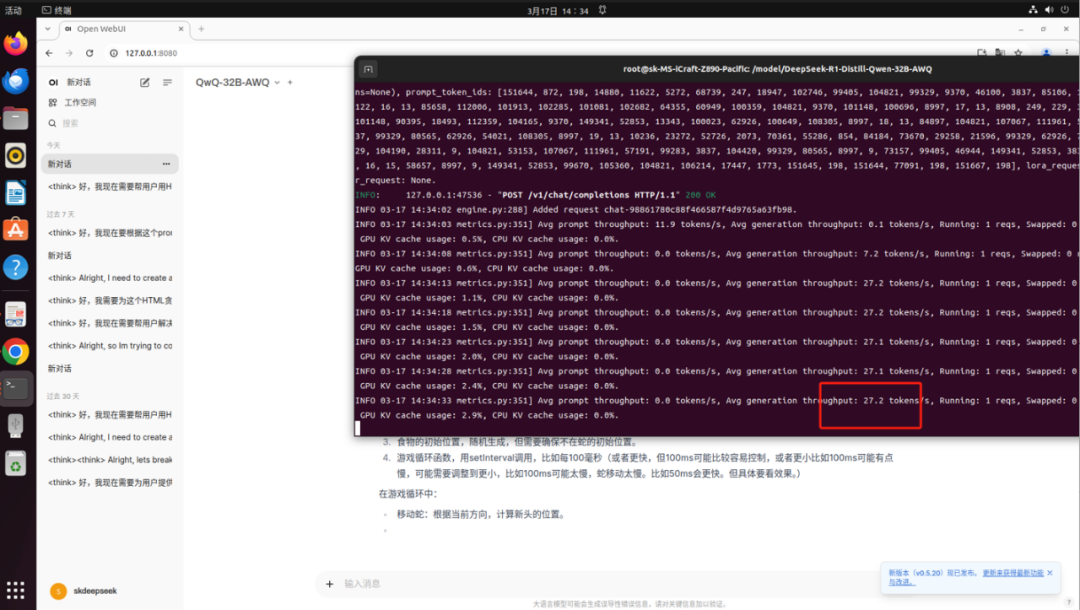
(QwQ-32B-AWQ运行速度实机截图)
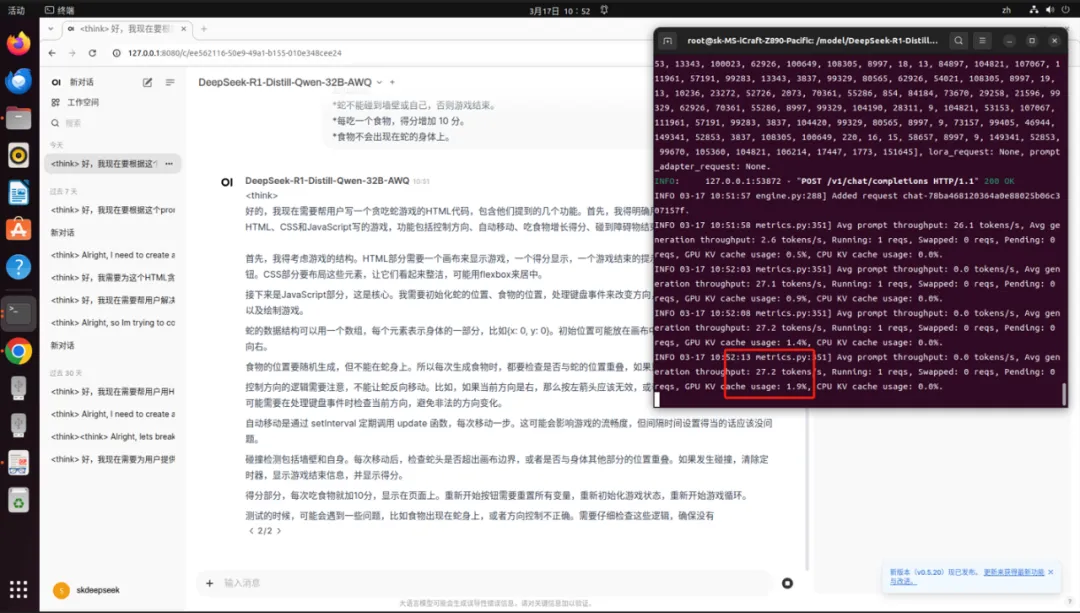
(DeepSeek-R1-Distill-Qwen-32B运行速度实机截图)
相较于Windows版本,通过Linux vLLM方案进行大模型的本地部署在多并发优化和多卡优化性能上有明显优势。基于vLLM的后端服务框架,能打造一个支持20路并发请求,单路推理速度达10+tokens/s的企业AI私有云,支持局域网内的所有用户同时访问。推荐铭瑄Z890主板搭配双Intel Arc A770显卡,打造万元级高配性价比整机方案,实现AI推理、内容输出高效流畅。
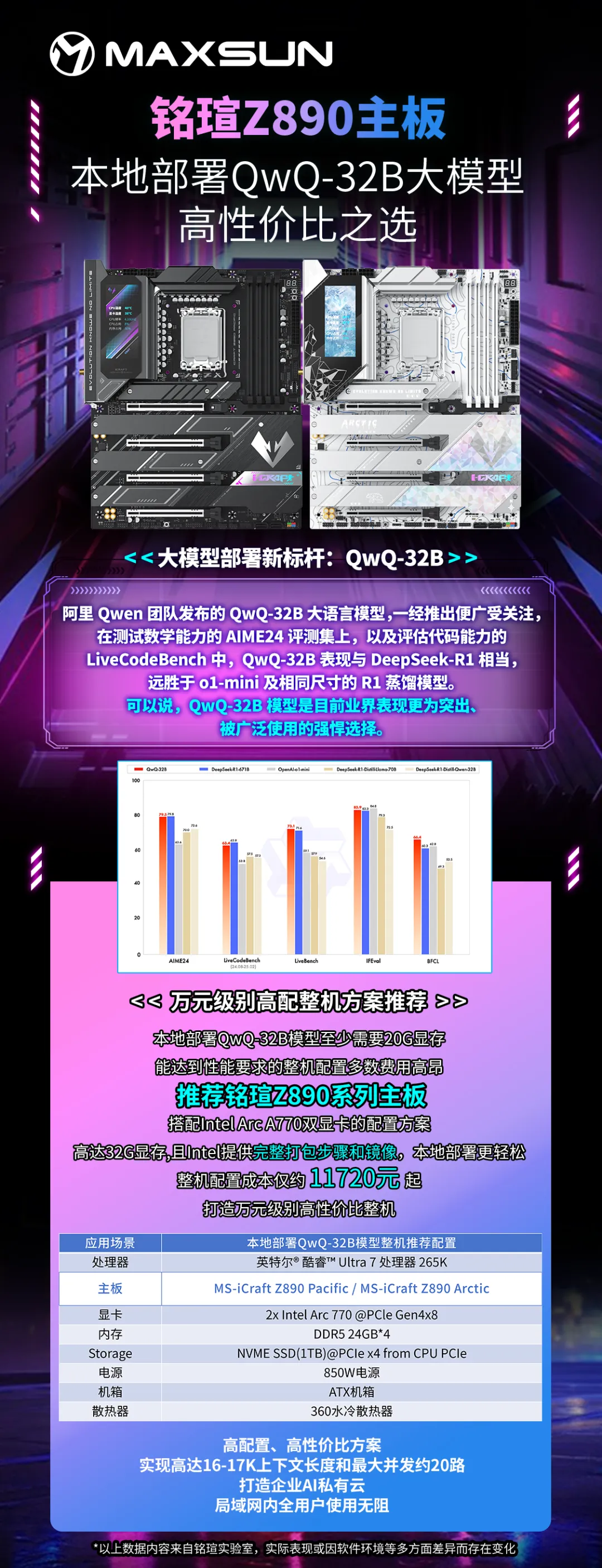
作为iCraft系列下的明星产品,MS-iCraft Z890 Pacific和MS-iCraft Z890 Arctic创新配备一块3.4英寸锐影LED显示屏,支持多种模式设置,除了可实时显示系统信息、个性化开关机画面外,还可开启桌面映射,同步显示专属画面或影像。供电方面,采用16+1+1相Dr.MOS直出供电,充分发挥CPU潜能。内存方面,配备4*高速DDR5内存插槽,超频冲击8800MHz,同时8层服务器级低损耗PCB和背钻工艺能有效降低信号损耗、增强信号完整性、助力DDR5高速传输。

快来选择一款铭瑄Z890主板,充分发挥性能潜力,让 32B 大模型的推理效率与并发能力突破极限吧!
